TL;DR: What is ROVED?
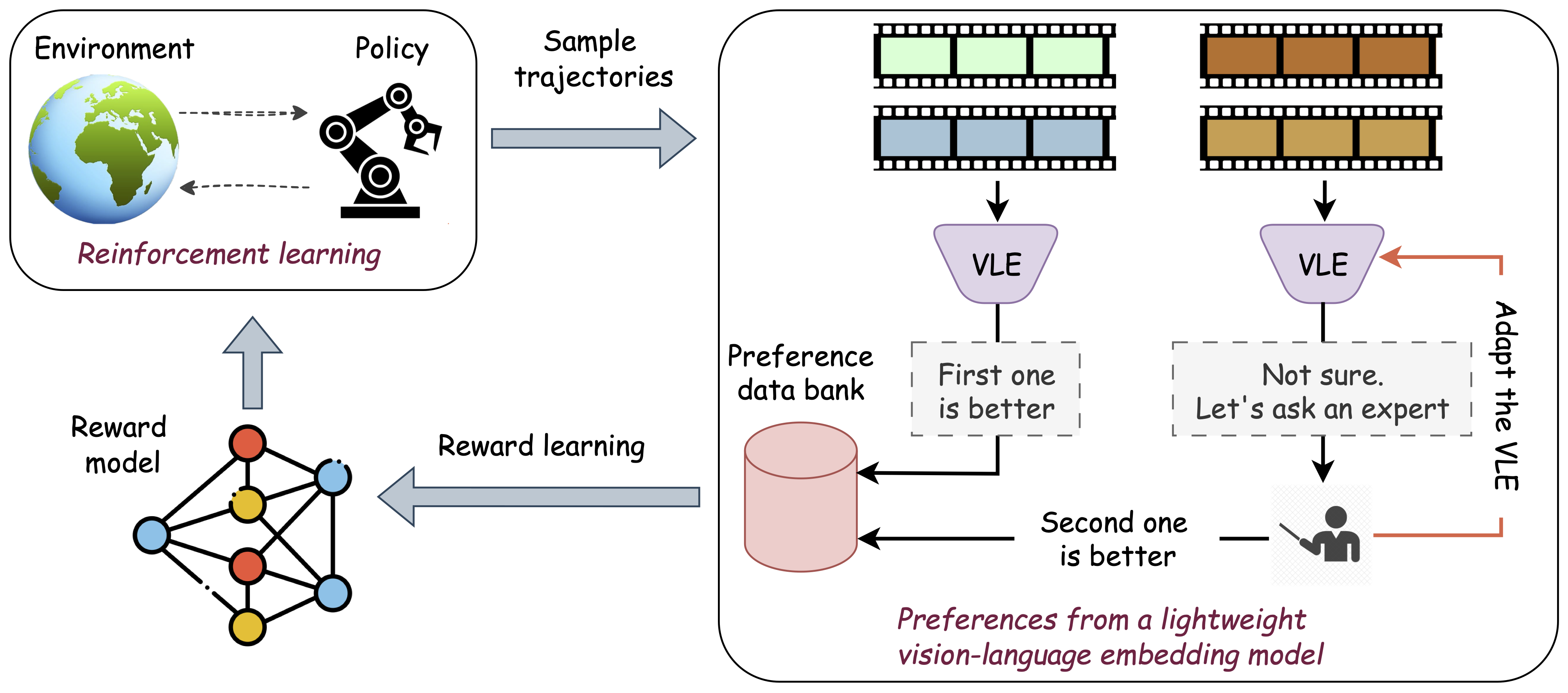
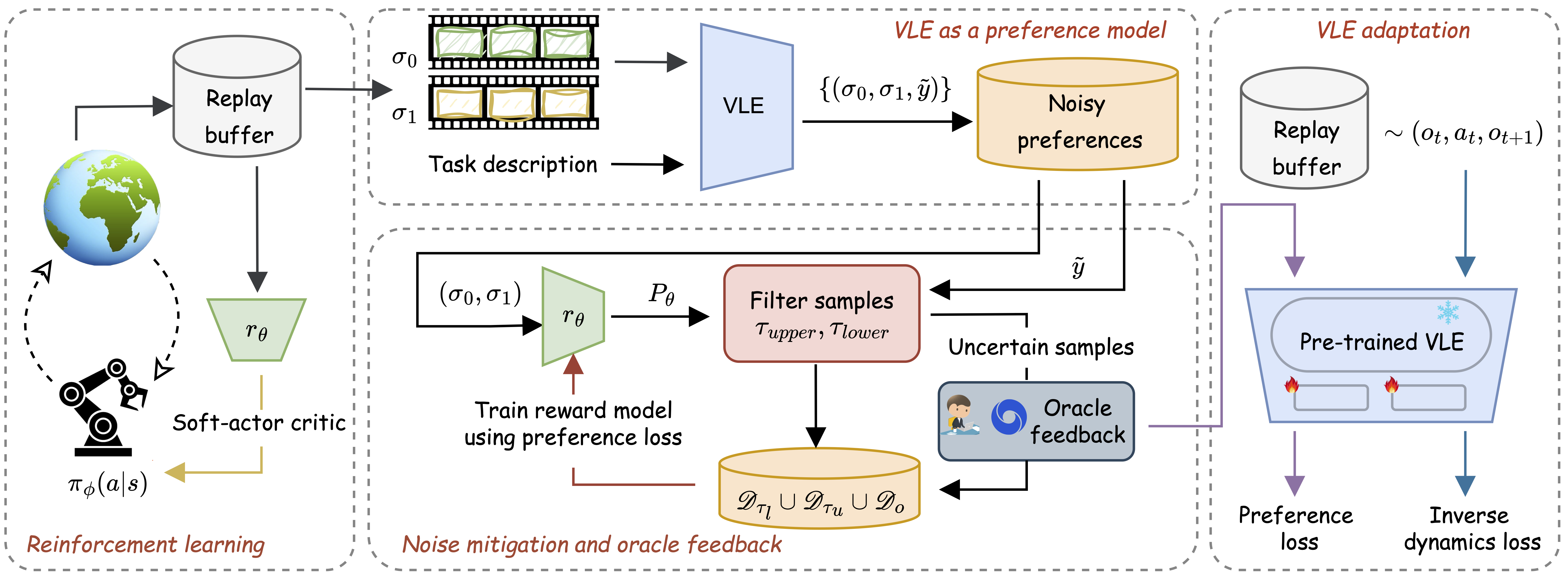
ROVED (Reducing Oracle Feedback with Vision-Language Embeddings) is a hybrid framework for preference-based reinforcement learning that combines scalable vision-language embedding (VLE) models with targeted oracle feedback. It works in two key stages:
1. VLE-based Preference Generation: The model uses lightweight VLE models to generate segment-level preferences for trajectory comparisons, providing a scalable alternative to expensive oracle annotations.
2. Selective Oracle Querying: Using a filtering mechanism with uncertainty thresholds (τupper and τlower), ROVED identifies noisy or uncertain samples and defers only these to the oracle for annotation, dramatically reducing annotation costs.
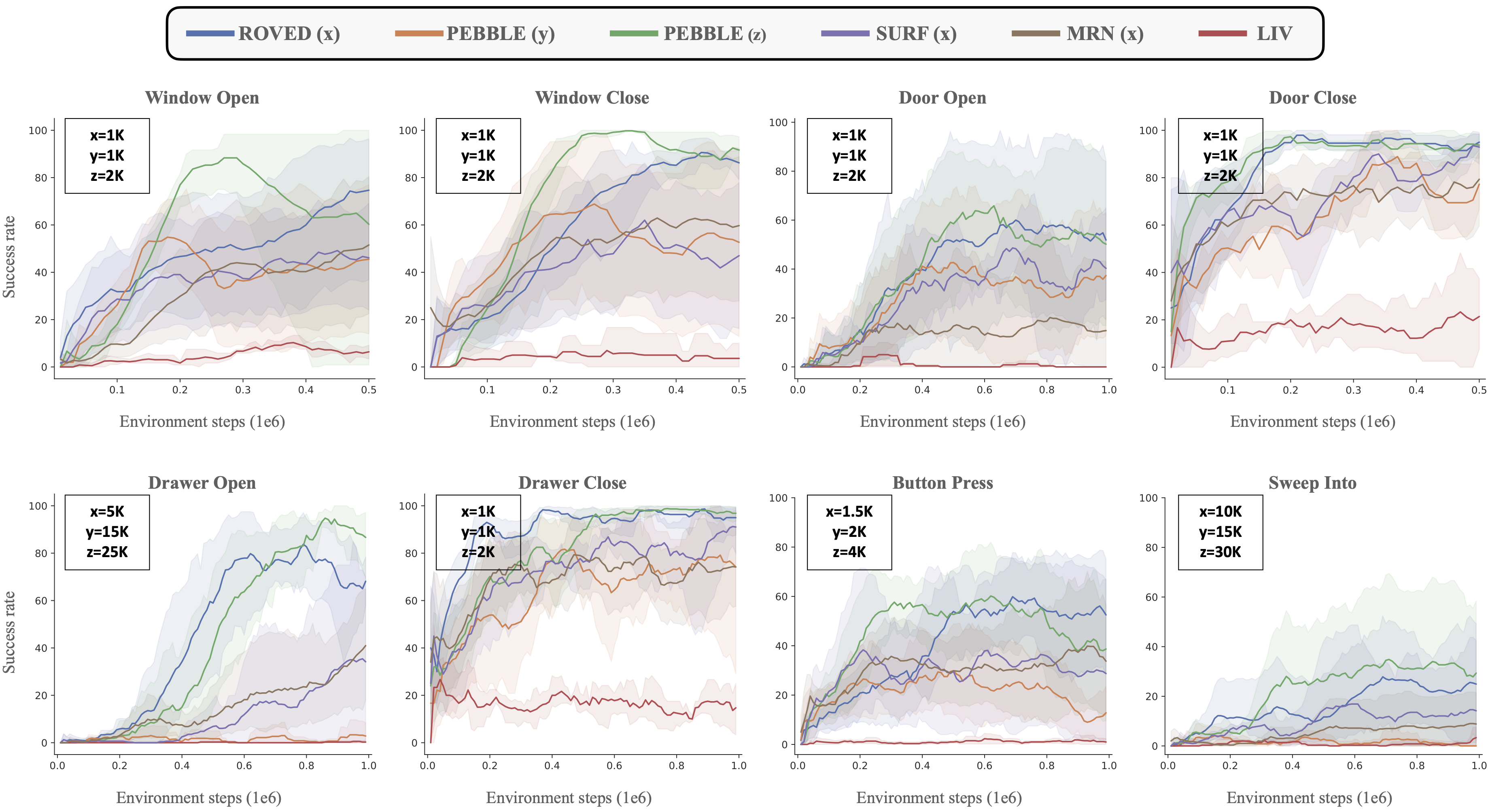
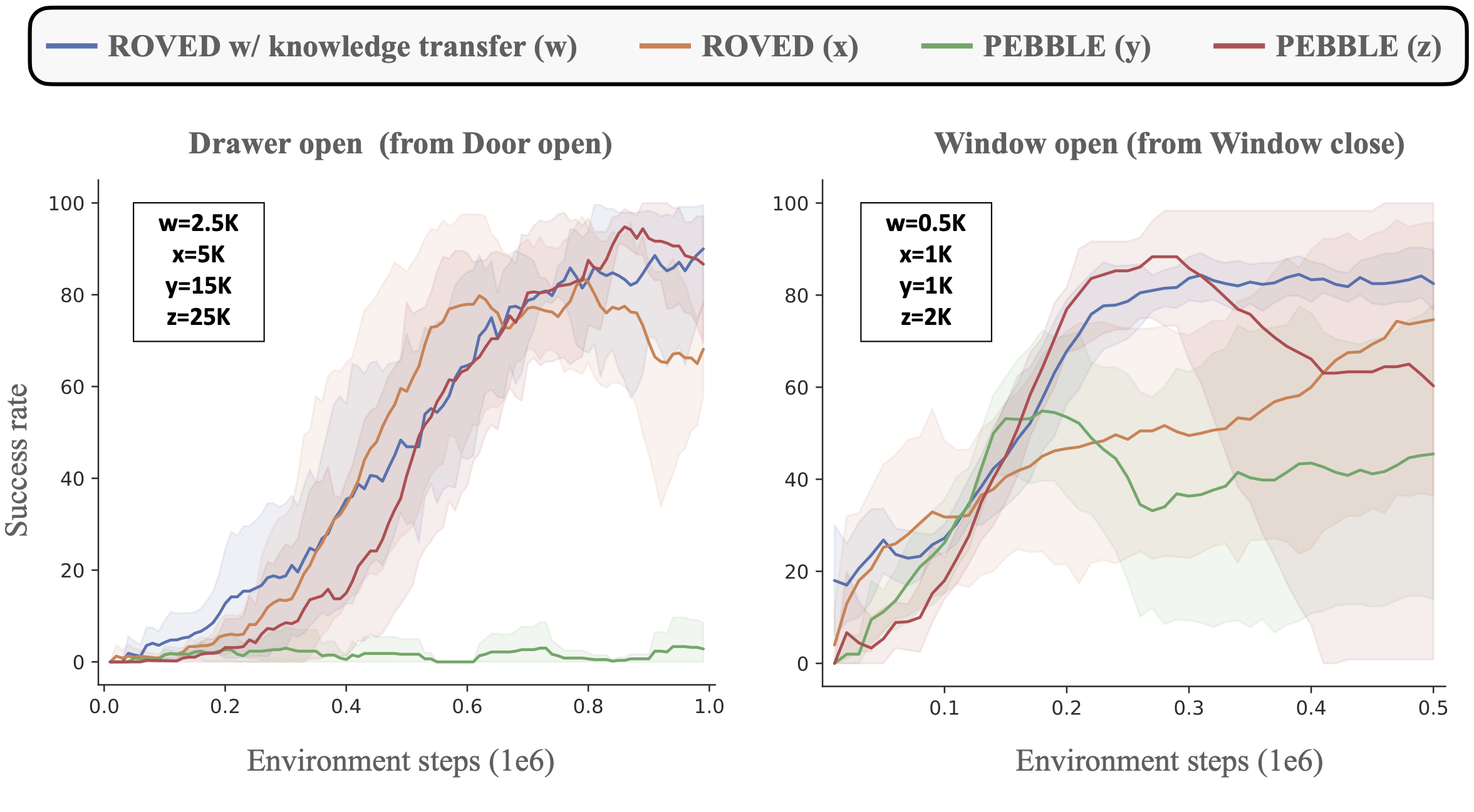
The framework also includes parameter-efficient fine-tuning that adapts the VLE using oracle feedback, creating a synergistic loop where the VLE improves over time. Across multiple robotic manipulation tasks, ROVED matches or surpasses prior methods while reducing oracle queries by up to 80% and achieving cumulative annotation savings of up to 90% through cross-task generalization.